


Next: Performance measurement
Up: Clustering Narrow-Domain Short Texts
Previous: Description of the FSTs
Experimental results
Clustering very short narrow-domain texts, implies basically two steps: first it is necessary to perform the feature selection process and after the clustering itself. We have used the three unsupervised techniques described in Section 3.5 in order to sort the corpora vocabulary in non-increasing order, with respect to the score of each FST. Thereafter, we have selected different percentages of the vocabulary (from 20% to 90%) in order to determine the behaviour of each technique under different subsets of the vocabulary. The following step involves the use of clustering methods; three different clustering methods were employed for this comparison: Single Link Clustering (SLC) [12], Complete Link Clustering (CLC)[12], and KStar [23].
In order to obtain the best description of our experiments, we have carried out a 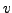 -fold cross validation evaluation [7]. This process implies to randomly split the original corpus in a predefined set of partitions, and then calculate the average
-fold cross validation evaluation [7]. This process implies to randomly split the original corpus in a predefined set of partitions, and then calculate the average 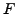 -measure (described in the next sub-section) among all the partitions results. The -fold cross-validation allows to evaluate how well each cluster ``performs'' when is repeatedly cross-validated in different samples randomly drawn from the data. Consequently, our results will not be casual through the use of a specific clustering method and a specific data collection. In our case, we have used five partitions for the CICLing-2002 corpus and, thirty for both, the hep-ex and the KnCr collections.
-measure (described in the next sub-section) among all the partitions results. The -fold cross-validation allows to evaluate how well each cluster ``performs'' when is repeatedly cross-validated in different samples randomly drawn from the data. Consequently, our results will not be casual through the use of a specific clustering method and a specific data collection. In our case, we have used five partitions for the CICLing-2002 corpus and, thirty for both, the hep-ex and the KnCr collections.
We have used the -measure for determining the quality of clusters obtained, as it is described in the next sub-section. Thereafter the results are presented and discussed.
Subsections
Next: Performance measurement
Up: Clustering Narrow-Domain Short Texts
Previous: Description of the FSTs
David Pinto
2007-05-08