


Next: Transition Point
Up: Term Selection and Weighting
Previous: Term Selection and Weighting
Determination of a set of words that characterize a set of
documents given, is the focus of our work. Given a set of documents
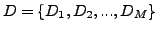 , and
, and 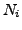 the number of words
in the document
the number of words
in the document 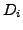 , the relative frequency of the word
, the relative frequency of the word
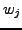 in is defined as follows:
in is defined as follows:
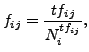 |
(2) |
and
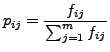 |
(3) |
is the probability of the word be in .
Thus, entropy of can be calculated as:
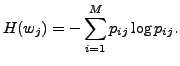 |
(4) |
The representation of a document is given by the VSM,
whenever terms have high entropy.
Let 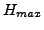 be the maximum value of entropy on all the terms,
be the maximum value of entropy on all the terms,
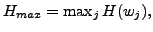 the representation based on entropy of is
the representation based on entropy of is
![$\displaystyle H_i=[w_j\in D_i\vert H(w_j)>H_{max}\cdot u],$](img38.png) |
(5) |
where 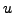 is a threshold which defines the level of high entropy. In our
experiments we have set
is a threshold which defines the level of high entropy. In our
experiments we have set 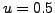 .
.
Next: Transition Point
Up: Term Selection and Weighting
Previous: Term Selection and Weighting
David Pinto
2007-05-08