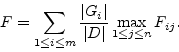![]() David Pinto &
David Pinto & ![]() Paolo Rosso
Paolo Rosso
(2) Faculty of Computer Science, B. Autonomous University of Puebla
Clustering is the most important unsupervised learning problem, due to its wide real possible applications. The goal of this task is to determine the intrinsic grouping in a set of unlabeled data. Nowadays there exist datasets widely used in classification, a clustering close-related task, like Reuters [1] and 20 Newsgroups 2.
Currently, Reuters is the most widely used test collection for text categorization research. The data was originally collected and labeled by Carnegie Group, Inc. and Reuters, Ltd. in the course of developing the CONSTRUE text categorization system. The most known version of Reuters used nowadays is Reuters-21578 [1], which contains four set of categories (EXCHANGES, ORGS, PEOPLE, and PLACES), where each one corresponds to named entities of the specified type. Differents subsets of Reuters-21578 have been constructed (ModApte, R10, R90, etc), but no one can be considered suitable for experiments in clustering short texts of narrow domain. On the other hand, 20 Newsgroups is a collection of 20.000 messages, collected from UseNet postings over a period of several months in 1993. The data are divided almost evenly among 20 different UseNet discussion groups and, therefore, is quite far to be a narrow domain corpus.
Clustering short texts of narrow domain task is a new challenging task that has been attended in just a few papers. For instance, in [2] Makaganov et al. presented simple procedures for clustering feature selection using two narrow-domain corpora. The first collection was made up of 48 abstracts from the computational linguistics and intelligent text processing conference (CICLing 2002)3, whereas the second was composed by 200 abstracts from the international federation of classificaton societies conference (IFCS-2000)4. The first corpus was also used by Alexandrov et al. [3], Jiménez et al. [4], and Pinto et al. [5] for their experiments in clustering abstracts in a narrow domain. However, this collection is very small and, therefore, the results obtained may be imprecise when a cross-validation evaluation is not used [6]. Recently, in [5] another short-text corpus in the particles physics domain was used for experiments in clustering; the size of it was approximately 2.000 abstracts, but the distribution of the topics was very unbalanced. The clustering of these kind of corpora implies a very big challenge if a correct performance measure is applied, because identifying a class with one element is more difficult than identifying another one with many elements. Moreover, in real situations this kind of corpora are very difficult to be found. From this viewpoint, we are interested in a moderate-sized and balanced corpus and, therefore, the aim of this work consists in gathering abstracts from a high quality source for constructing a balanced corpus suitable for experiments in clustering short texts of the narrow cancer domain. We have selected MEDLINE for extracting those documents that are related with the cancer topics. In this way, we have structured this paper for explaining the characteristics of this new corpus and the hardness of clustering the documents inside it. Section 2 presents a brief introduction of the MEDLINE repository. In Section 3 we describe the composition of the KnCr corpus. Moreover, a set of experiments carried out in order to determine the hardness of clustering the content this new corpus are shown. Finally, a discussion is presented.
The National Library of Medicine (NLM) collects materials in all areas of biomedicine and health care, as well as works on biomedical aspects of technology, the humanities, and the physical, life, and social sciences. The collections stand at more than 8 million items-books, journals, technical reports, manuscripts, microfilms, photographs and images. NLM is a national resource for all U.S. health science libraries through a National Network of Libraries of Medicine.
Althought the last annual statistical profile of NLM, given in September 2005, stands this collection in 606.000 articles indexed from 4.900 journals for MEDLINE, the access to the complete collection is not free available for all people; MEDLINE data is licensed by the NLM at low cost to anyone who wants to make the information available to a user group. Moreover, a sample data for experiments is provided5; for instance, the last sample file ``medsamp2006f.xml'' is about 20,5MB.
The use of MEDLINE in literature is wide extended. Several works use this collection for different tasks (see http://www.nlm.nih.gov/bsd/licensee/reports/name.html). The last sample provided by NLM contains abstracts, texts, and sometimes just the title and authors from the medicine domain investigations and, therefore, in order to construct a short text narrow domain corpus, an analysis of such documents have to be done for selecting those that have both, abstract and keywords. The process for the construction of this new corpus is described in the next section.
The absence of a specific forum for the evaluation of systems for the clustering short text narrow-domain task, has not allowed to create a good corpus for using it as a standard evaluation. We have done several experiments on constructing new narrow domains corpora, specifically in the medicine domain. Currently, we have constructed one, by downloading the last sample of documents provided by MEDLINE6, which contains approximately 30.000 abstracts, and selecting those related with the ``Cancer'' domain. In the following subsections we will explain how we have created the gold standard for this new corpus.
In order to correctly evaluate results of clustering, a corpus must be provided with a gold standard of the possible clustering classes distribution. Although the gold standard is normally constructed by humans, we tried to create it automatically.
Due to the fact that each retrieved abstract of our document set contains ``keywords'' provided by each author, we used them for constructing the gold standard for this collection. We selected three clustering methods for this experiment, two are already implemented in the Weka machine learning software [7]: Expectation Maximization (EM) and K-Means. The third clustering method is KStar [8]. We used the F-Measure [9] for comparing each pair of clustering methods. The formula used is described as follows:
Given a set of clusters
![]() and a set of classes
and a set of classes
![]() , the F-measure between a cluster
, the F-measure between a cluster ![]() and a class
and a class ![]() is given by the following formula.
is given by the following formula.
| (1) |
| (2) |
| (3) |
The global performance of a clustering method is calculated by using the values of ![]() , the cardinality of the set of clusters obtained, and normalizing by the total number of documents in the collection (
, the cardinality of the set of clusters obtained, and normalizing by the total number of documents in the collection (![]() ). The obtained measure is named F-measure and it is shown in equation 4.
). The obtained measure is named F-measure and it is shown in equation 4.
The results obtained are presented in Table 1. None pair combination of clustering methods obtained more than 0,51 of F-Measure and it was not possible to determine a winner clustering method for constructing the gold standard. This first experiment has shown that clustering narrow-domain corpora is really a difficult task, eventhought we have available the keywords of each abstract.
Once obtained the previous results, we had to do manual inspection for classifying every document in its correct class for constructing the gold standard. We used the ontology made available by the National Cancer Institute (NCI)7, in order to construct the gold standard categories. This ontology describes a hierarchy of cancer terms based in the anatomy kind and specifies the fine grain categories of this domain (the current owl version of the NCI thesaurus can be found in http://www.mindswap.org/2003/CancerOntology/). Table 2 and 3 show the complete characteristics of this new cancer corpus. As can be seen, only 900 from 30.000 abstracts are related with the cancer topic, and the average length of each of them is about 126 words which makes it suitable for experiments in the task described before.
| Category | # of abstracts |
| blood | 64 |
| bone | 8 |
| brain | 14 |
| breast | 119 |
| colon | 51 |
| genetic studies | 66 |
| genitals | 160 |
| liver | 29 |
| lung | 99 |
| lymphoma | 30 |
| renal | 6 |
| skin | 31 |
| stomach | 12 |
| therapy | 169 |
| thyroid | 20 |
| Other (XXX) | 22 |
| Total | 900 |
| Feature | Value |
| Size of the corpus (bytes) | 834.212 |
| Number of categories | 16 |
| Number of abstracts | 900 |
| Total number of terms | 113.822 |
| Vocabulary size (terms) | 11.958 |
| Terms average per abstract | 126,47 |
Once constructed the gold standard, we carried out some experiments to compare different methods of clustering against it, in order to investigate the hardness of clustering the texts that made up this corpus. We implemented two hierarchical clustering methods, namely Single and Complete Link Clustering (SLC, CLC) [10], and three agglomerative clustering methods (K-NN [11], KStar [8], NN1 [4]). The results obtained by clustering the abstracts instead of the keywords, and by using two well known vocabulary reduction techniques (Document Frequency-DF and Term Strength-TS) [12], are presented in Table 4. We can observe low F-measure values for each clustering method, which highlights again the hardness of this task.
In order to verify whether the clustering by keywords, provided by abstract authors, behaves better than using the vocabulary reduction techniques presented above, we carried out a third experiment: in this case we compared the results obtained by clustering those keywords with EM, KMeans and KStar methods with the gold standard built manually. The results are presented in Table 5. We can see that using keywords instead of abstracts can lead to more confusion in the clustering short texts narrow-domain task. This may be due to the different viewpoints of scientific text author, and the few words added as keywords. That is, a little variation in the keyword set leads to classify similar documents as different. We consider that more investigation must be done in order to clearly determine this behaviour.
Up to now, clustering very short texts of narrow domains has not received too much attention by the computational linguistic community and only few are the related works which can be found in literature. This could be derived from the high challenge that this problem implies, since the obtained results are very unstable or imprecise when clustering abstracts of scientific papers, technical reports, patents, etc. As a consequence, there exist a lackness of this type of corpora that led us to compile scientific abstracts from high quality sources. We have selected MEDLINE as a repository source for the construction of a new corpus in the cancer domain. Our corpus is a moderate sized one, with 900 abstracts and 16 different balanced categories.
In order to investigate the possible hardness of clustering this corpus, we have carried out a set of experiments. First we tried to construct automatically the gold standard by comparing three different clustering methods upon the use of the keywords of each abstract. Due to the difficulty to evaluate the goodness of the automatically obtained gold standard, we decided to obtain it manually. Moreover, we compared the results of clustering keywords against clustering abstracts (using a vocabulary reduction), and in this particular case we found that author keywords may confuse the clustering process. Further analysis should investigate this behaviour.
We have made free available this new corpus by email request to authors considering that this corpus, together with its gold standard, will allow to test algorithms for clustering very short texts of the cancer narrow domain.