


Next: Experimental Results
Up: Clustering of Abstracts in
Previous: Data Set
We used 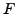 -measure (commonly used in information retrieval [16]) in order to determine which method obtains the best
performance. Given a set of clusters
-measure (commonly used in information retrieval [16]) in order to determine which method obtains the best
performance. Given a set of clusters
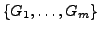 and a set of classes
and a set of classes
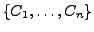 , the -measure between a cluster
, the -measure between a cluster
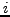 and a class
and a class 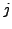 is given by the following formula.
is given by the following formula.
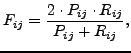 |
(3) |
where
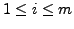 ,
,
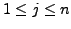 .
. 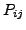 and
and 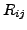 are defined as follows:
are defined as follows:
 |
(4) |
and
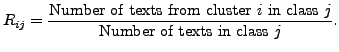 |
(5) |
The global performance of the clustering is calculated using the values of 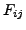 . This measure is named measure and it is shown
as follows:
. This measure is named measure and it is shown
as follows:
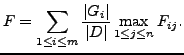 |
(6) |
David Pinto
2006-05-25