Let ![]() be the text collection composed by the texts whose terms have
been obtained by applying of TP method and including
be the text collection composed by the texts whose terms have
been obtained by applying of TP method and including ![]() terms closer to
terms closer to ![]() from each original text. Let
from each original text. Let ![]() be the vocabulary of
be the vocabulary of ![]() and
and
![]() the average of
the average of ![]() for terms
for terms ![]() that belong to
that belong to
![]() but not to
but not to ![]() .
.
![]() value is linked to the
similarity among the texts. Clearly lowest value of
value is linked to the
similarity among the texts. Clearly lowest value of
![]() is 1,
and it means the new terms added to
is 1,
and it means the new terms added to ![]() are not shared by the texts of
are not shared by the texts of
![]() . In our experiments it was observed that a decreasing of
. In our experiments it was observed that a decreasing of
![]() (
(
![]() ) contributed to change instances
from an incorrect cluster to a correct one.
Therefore, terms with low
) contributed to change instances
from an incorrect cluster to a correct one.
Therefore, terms with low
![]() help to distribute texts
into the clusters; the decreasing of
help to distribute texts
into the clusters; the decreasing of
![]() , the decreasing of
similarity between texts. Now, we can define an indicator of the
goodness of a selection
, the decreasing of
similarity between texts. Now, we can define an indicator of the
goodness of a selection ![]() .
.
Whenever the number of clusters (![]() ) decreases after apply clustering to
) decreases after apply clustering to
![]() , a lower
, a lower
![]() value means that new terms added to vocabulary
value means that new terms added to vocabulary
![]() will provide rising of similarity between texts in
will provide rising of similarity between texts in ![]() . In such
conditions
. In such
conditions
![]() indicates a good selection. A way to express
the above description is to say that a good clustering supposes that
indicates a good selection. A way to express
the above description is to say that a good clustering supposes that
![]() be greater than
be greater than
![]() and
and ![]() be
greater than
be
greater than ![]() . We define the goodness of selection
. We define the goodness of selection ![]() as:
as:
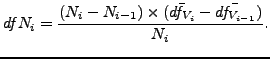 |
(7) |
In Table 3 a neighbour of maximum value of ![]() is shown.
Row 1 is
is shown.
Row 1 is ![]() , the number of terms selected by TP method, row 2 the size of
vocabulary of
, the number of terms selected by TP method, row 2 the size of
vocabulary of ![]() , row 3 normalized values of
, row 3 normalized values of ![]() , and in row
4 the
, and in row
4 the ![]() measure.
measure.
| i | 20 | 21 | 22 | 23 | 24 |
| 1,572 | 1,619 | 1,661 | 1,706 | 1,744 | |
| 0.573 | 0.621 | 1.027 | 0.584 | 0.990 | |
| 0.637 | 0.6411 | 0.6415 | 0.636 | 0.551 |