


Next: Clustering the datasets
Up: On the Relative Hardness
Previous: Datasets
Calculating the relative hardness of a corpus
In order to determine the Relative Hardness (RH) of a given corpus, we have considered the vocabulary overlapping among the texts of the corpus. In our experiments, we have used the well-known Jaccard coefficient for calculating the overlapping. We considered all the possible combinations of more than two categories from the corpus and for each of them we calculated its RH. For instance, for a given corpus of 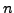 categories,
categories,
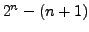 possible subcorpora will be obtained: e.g. for the R8 (eight categories) we obtained
possible subcorpora will be obtained: e.g. for the R8 (eight categories) we obtained 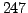 subsets.
subsets.
Thereafter, we calculated their RHs as follows: given a corpus 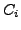 made up of categories (CAT), the RH of
made up of categories (CAT), the RH of
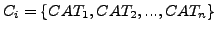 is:
is:
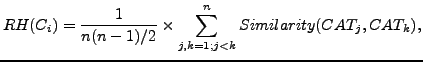 |
(1) |
where the similarity among categories is obtained by using the Jaccard coefficient in order to determine their overlapping (see Eq. (2)). However, more sophisticated measures also could be used, such as the one presented in [8] in the plagiarism degree calculation framework.
 |
(2) |
In the above formula we have considered each category 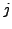 as the ``document'' obtained by concatenating all the documents belonging to the category .
as the ``document'' obtained by concatenating all the documents belonging to the category .
Next: Clustering the datasets
Up: On the Relative Hardness
Previous: Datasets
David Pinto
2007-10-05