


Next: The Penalisation-Based Ranking Approach
Up: A Penalisation-Based Ranking Approach
Previous: Introduction
The EuroGOV corpus preprocessing phase has presented a big challenge, due to the written different variants of the government web pages. We have found that a big amount of documents do not present a strict html syntax and, therefore, we have written two scripts for obtaining the index terms of each document. The first script uses regular expressions for excluding all the information which
is enclosed by the characters 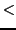 and
and 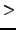 . This script obtains very good
results, but it is very slow and, therefore, we decided to used it only with three domains of the
EuroGOV collection, namely Spanish (ES), French (FR), and German (DE). On the other hand, we wrote a script based in the html syntax for obtaining all the terms considered interesting for indexing.
This script speeded up our indexing process but it did not took into account that some web pages
do not strictly observe the html syntax; and, therefore, we missed important information from those documents.
. This script obtains very good
results, but it is very slow and, therefore, we decided to used it only with three domains of the
EuroGOV collection, namely Spanish (ES), French (FR), and German (DE). On the other hand, we wrote a script based in the html syntax for obtaining all the terms considered interesting for indexing.
This script speeded up our indexing process but it did not took into account that some web pages
do not strictly observe the html syntax; and, therefore, we missed important information from those documents.
Although the EuroGOV corpus is given in UTF-8, the documents that made up this corpus do not neccesarily keep this codification. We have seen that for some domains, the charset codification is given in the html metadata tag, but also we have found that very often this codification is wrong. We consider the charset codification detection the most difficult problem in the preprocessing step.
As usual in the information retrieval systems, we eliminated stop words for each language (except Greek) and punctuation
symbols. A good repository of resources for this step is suministered by Jacques Savoy from the Institut interfacultaire d'informatique![[*]](file:/usr/share/latex2html/icons/footnote.png) . A variation on the elimination of diacritics was done; we discuss into detail this approach in Section 4. The same process was applied to the queries. The next section discusses the model we have used in our runs.
. A variation on the elimination of diacritics was done; we discuss into detail this approach in Section 4. The same process was applied to the queries. The next section discusses the model we have used in our runs.
Next: The Penalisation-Based Ranking Approach
Up: A Penalisation-Based Ranking Approach
Previous: Introduction
David Pinto
2007-05-08