


Next: Description of the FSTs
Up: Feature Selection Techniques
Previous: Feature Selection Techniques
The Transition Point Technique
The Transition Point (TP) is a frequency value that splits the vocabulary of a
document into two sets of terms (low and high frequency). This technique
is based on the Zipf Law of Word Ocurrences [Zipf1949] and also on the refined
studies of Booth [Booth1967], as well as Urbizagástegui [Urbizagástegui1999]. These
studies are meant to demonstrate that terms of medium frequency are
closely related to the conceptual content of a document. Therefore, it is
possible to form the hypothesis that terms whose frequency is closer to TP can be used as indexes of
a document. A typical formula used to obtain
this value is given in equation 1:
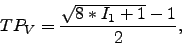 |
(1) |
where 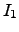 represents the number of words with frequency equal to
represents the number of words with frequency equal to 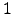 in the text
in the text 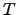 [Moyotl and Jiménez2004b] [Urbizagástegui1999]. Alternatively,
[Moyotl and Jiménez2004b] [Urbizagástegui1999]. Alternatively, 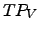 can be localized by identifying the lowest frequency (from the highest
frequencies) that it is not repeated; this characteristic comes from the properties of Booth's
law for low frequency words [Booth1967].
can be localized by identifying the lowest frequency (from the highest
frequencies) that it is not repeated; this characteristic comes from the properties of Booth's
law for low frequency words [Booth1967].
Let us consider a frequency-sorted vocabulary
of a text T; i.e.,
with
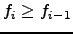 , then
, then
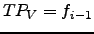 , iif
, iif 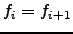 . The most important words are
those that obtain the closest frequency values to TP, i.e.,
. The most important words are
those that obtain the closest frequency values to TP, i.e.,
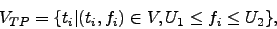 |
(2) |
where 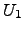 is a lower threshold obtained by a given neighbourhood
value of the TP, thus,
is a lower threshold obtained by a given neighbourhood
value of the TP, thus,
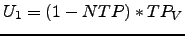 (
(![$NTP\in[0,1]$](img13.png) ).
). 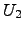 is the
upper threshold and it is calculated in a similar way (
is the
upper threshold and it is calculated in a similar way (
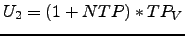 ).
).
The TP technique has been used in different areas of Natural Language Processing
like: clustering of short texts [Jiménez, Pinto, and Rosso2005a], categorization of texts [Moyotl and Jiménez2004a] [Moyotl-Hernández and
Jiménez-Salazar2005],
keyphrases extraction [Pinto and Pérez2004] [Tovar
2005], summarization [Bueno, Pinto, and Jiménez-Salazar2005],
and weighting models for information retrieval systems [Cabrera, Pinto, and H. Jiménez2005]. Therefore,
we believe that there exists enough evidence to use this technique
as a term selection process.
Next: Description of the FSTs
Up: Feature Selection Techniques
Previous: Feature Selection Techniques
David Pinto
2006-05-25