


Next: Experimental results
Up: Feature Selection Techniques
Previous: The Transition Point Technique
- Document Frequency (DF): This technique assigns the value
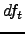 to each term
to each term 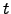 , where means the number of texts, in a
collection, where ocurrs. This technique assumes that low frequency terms will rarely appear in other documents, therefore,
they will not have significance on the prediction of the class for this text.
, where means the number of texts, in a
collection, where ocurrs. This technique assumes that low frequency terms will rarely appear in other documents, therefore,
they will not have significance on the prediction of the class for this text.
- Term Strength (TS): The weight given to each term is defined by the following equation:
where
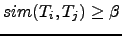 , and
, and 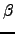 is a threshold that must be tuned by reviewing the similarity matrix. A high value of
is a threshold that must be tuned by reviewing the similarity matrix. A high value of
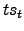 means that the term contributes to the texts
means that the term contributes to the texts 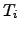 and
and 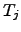 to be more similar than .
A more detailed description can be found in [Yang1995].
to be more similar than .
A more detailed description can be found in [Yang1995].
- Transition Point (TP): A higher value of weight is given to each term , as its frequency is closer to the TP frequency,
named
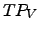 . The following equation shows how to calculate this value:
. The following equation shows how to calculate this value:
where 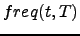 is the frequency of the term in the document
is the frequency of the term in the document 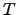 .
.
The unsupervised techniques presented here are the most successful in the clustering area. Particulary, DF is an effective and simple
technique, and it is known that it obtains comparable results to the classical supervised techniques
like 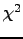 (CHI) and Information Gain (IG) [Sebastiani2002]. TP also has a simple calculation procedure, and as it was seen in
subsection 2.1, it can be used in different areas of NLP. The DF and TP techniques have a temporal linear complexity with respect to
the number of terms of the data set. On the other hand, TS is computationally more expensive than DF and TP, because it requires to
calculate a
similarity matrix of texts, which implies this technique to be in
(CHI) and Information Gain (IG) [Sebastiani2002]. TP also has a simple calculation procedure, and as it was seen in
subsection 2.1, it can be used in different areas of NLP. The DF and TP techniques have a temporal linear complexity with respect to
the number of terms of the data set. On the other hand, TS is computationally more expensive than DF and TP, because it requires to
calculate a
similarity matrix of texts, which implies this technique to be in 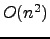 , where
, where 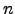 is the number of texts in the data set.
is the number of texts in the data set.
Next: Experimental results
Up: Feature Selection Techniques
Previous: The Transition Point Technique
David Pinto
2006-05-25